
This blog post describes how you can read Power BI Dataflow data with Azure Synapse On-Demand SQL.
Power BI service has a special functionality called Power BI Dataflow (https://docs.microsoft.com/en-us/power-bi/transform-model/dataflows/dataflows-introduction-self-service). It allows business users to create data wrangling pipelines, read data from various sources and save it to Azure Datalake Gen2 account.
Dataflow data is useable within Power BI. You can create reports on top of the data contained in dataflows. There are also readers for Python and some other programming languages. Unfortunately there is no reader currently for Azure Synapse Analytics On-Demand SQL.
Azure Synapse Analytics is a new Data Platform umberella from Microsoft (https://azure.microsoft.com/en-us/services/synapse-analytics/). It contains fully compliant T-SQL endpoint for querying data that is located on various sources. Here we are interested about data that sits on Azure Storage.
I have a customer who really needs this functionality as he does not use only Power BI to read but also would like for example use Excel or 3rd party tools to query imported dataflows. If the data would be available from t-sql view then it would be easily accessible.
Pre-requirements – How to map and link Datalake
I got comment from Youtube where it would be necessary to explain how to link Datalake to Power BI and to On-Demand SQL. This is very well explained from Microsoft documentation so I will only link it to here.
Link Datalake to your Power BI Workspace: https://docs.microsoft.com/en-us/power-bi/transform-model/dataflows/dataflows-azure-data-lake-storage-integration
Link your Datalake to Synapse On-Demand. https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-storage-files-overview?tabs=direct-access This is a bit more difficult. You can link with identity passthrough or with SAS tokens. But they are all explained at Microsoft Documentation.
Demo and walk-through
Power BI Dataflow data structure
Power BI Dataflow uses following structure in Datalake Gen2:
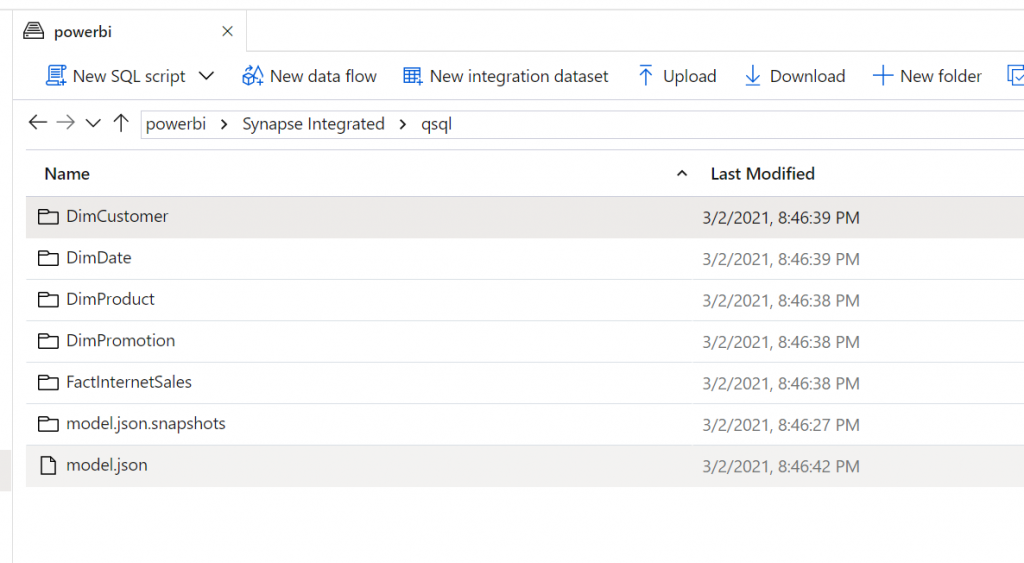
Power BI creates container “powerbi” for Storage Account. Under that container there will be a folder for workspace and then folder for dataflow. In this example workspace is “Synapse Integrated” and dataflow is “qsql”.
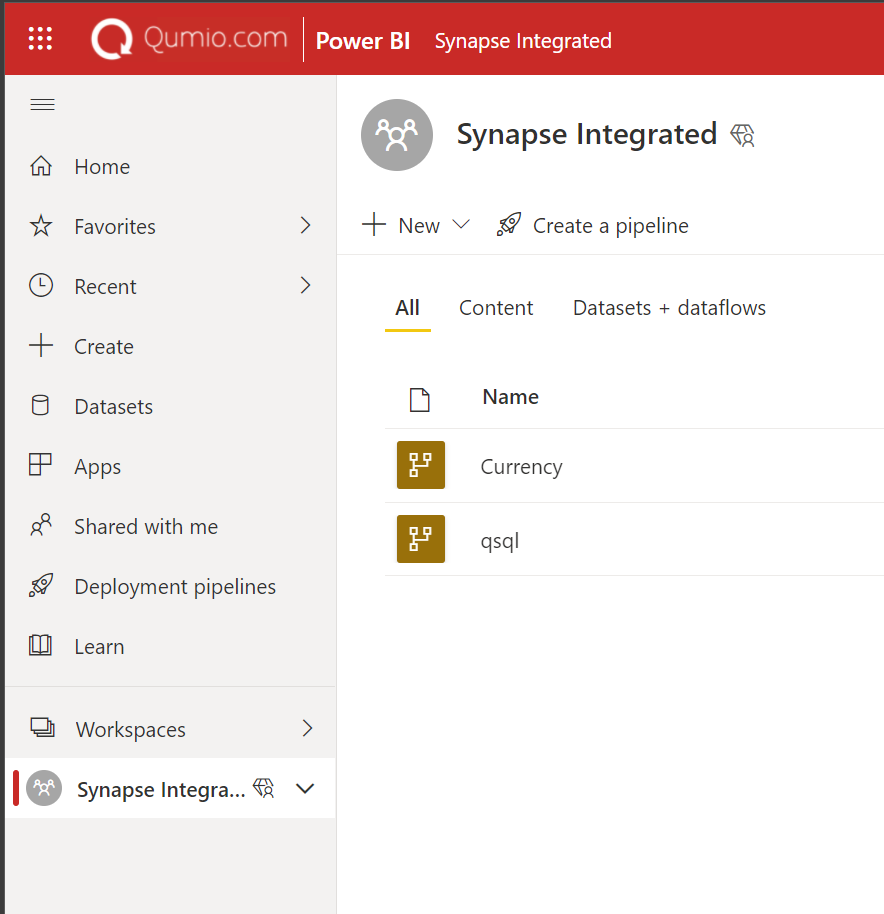
model.json file contains information about all the entities. Actual entities and their data is stored in folders.
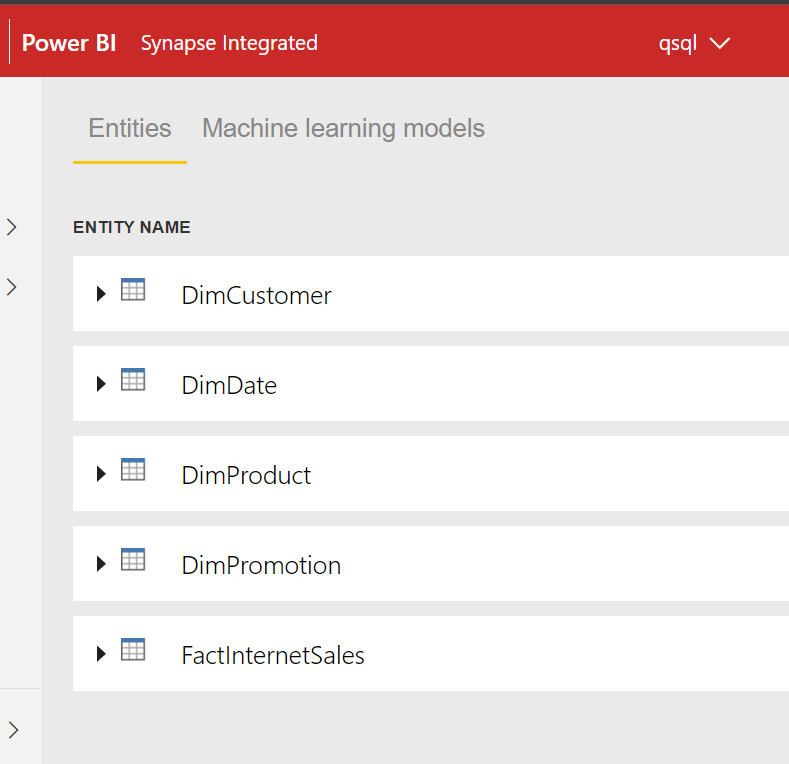
You can see that as the Dataflow has entity DimCustomer then Datalake Gen2 has a folder for DimCustomer.
Model.json describes the content. It has description for each entity, its fields and actual datafiles that should be included for the entity.
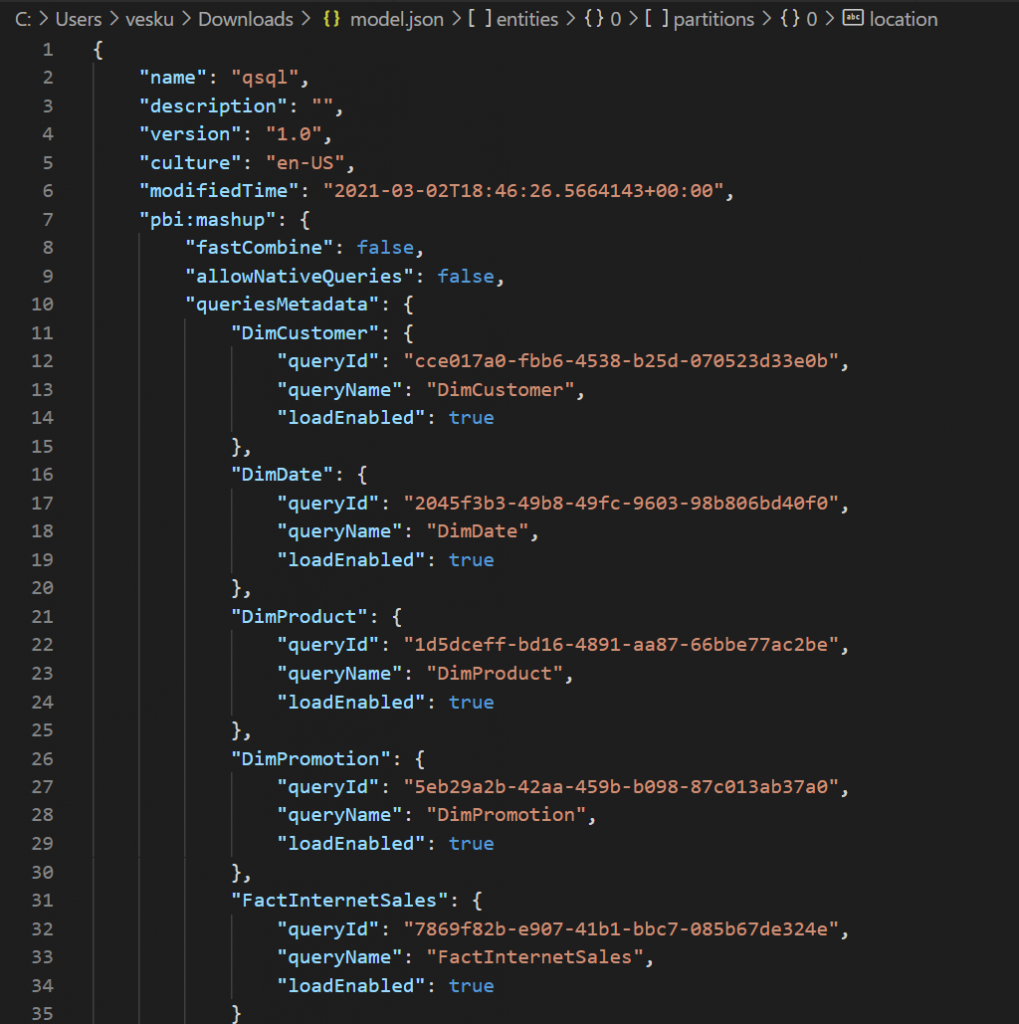
Datafiles and versioning
When you refresh your dataflow, Power BI will save new version of the entity data. It can be found from Datalake.
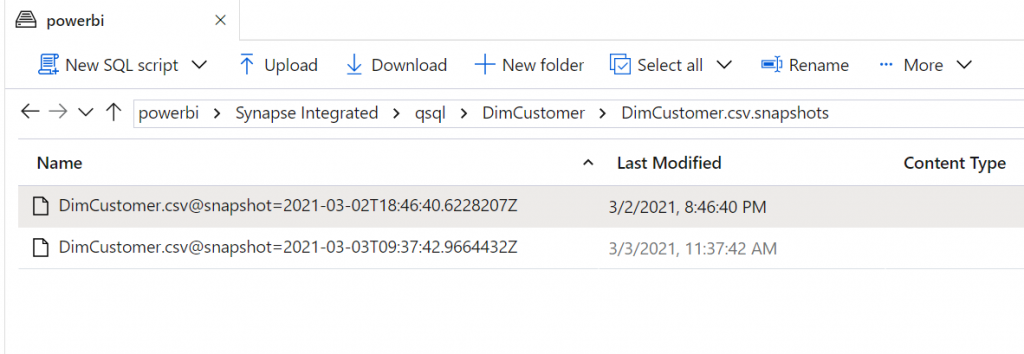
Model.json file describes which of these files are used to read the data.
How to read data?
Ok, enough for CDM data description. How can I read that data? We need to iterated through model.json files as they contain the required information.
I created a view [powerbi].[PowerBIModels] that does exactly that.
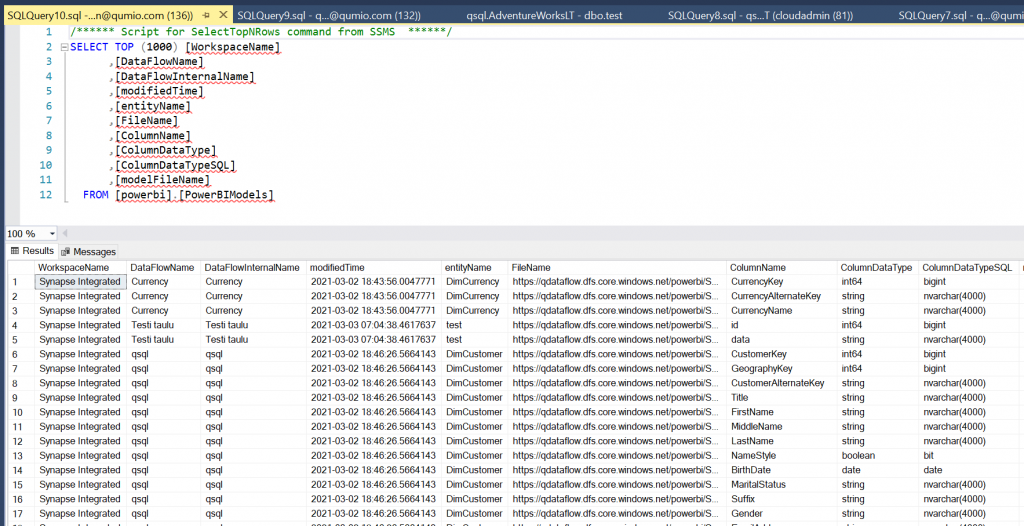
You can query that view to find what dataflows you have. What columns there are and what are the filenames behind.
This is not enough, we need to create the actual view from this information that would read the CDM data. This is done with the Stored Procedure [powerbi].[createModelView]

It takes 3 parameters.
- Workspace name
- Dataflow name
- Entity name
After you run the procedure it creates a view for you. Name of the view is in format: [powerbi].[workspace name_dataflowname_entity-name]
Example: [powerbi].[Synapse Integrated_qsql_DimCustomer]
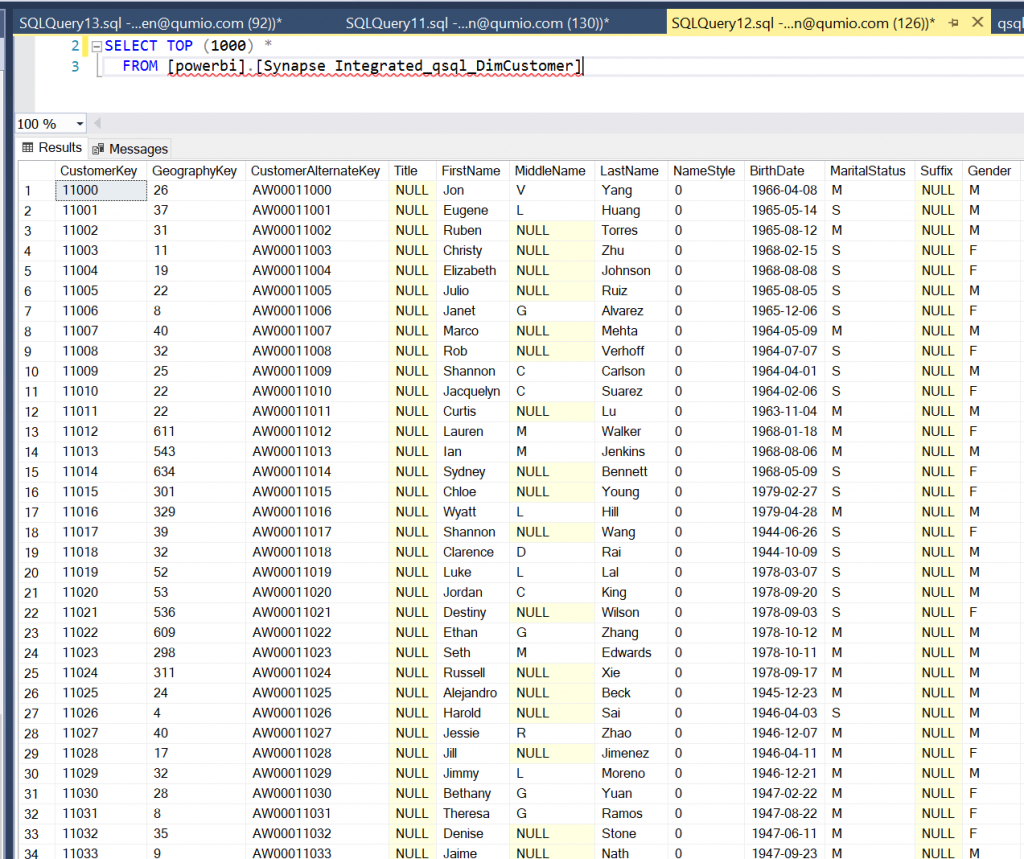
Data is easy to query. Data remains same until we refresh the view.
View is refreshed by re-running the procedure.
Code..
Ok, sounds interesting? Where do I find the code? I created a public Github repo and uploaded these scripts there. Feel free to download them from: https://github.com/vesatikkanen/Synapse-PowerBI-DataFlow-Reader
And yes, if you want to enchange the script someway you can do so and if you are willing to share your enhancements I would be very happy!