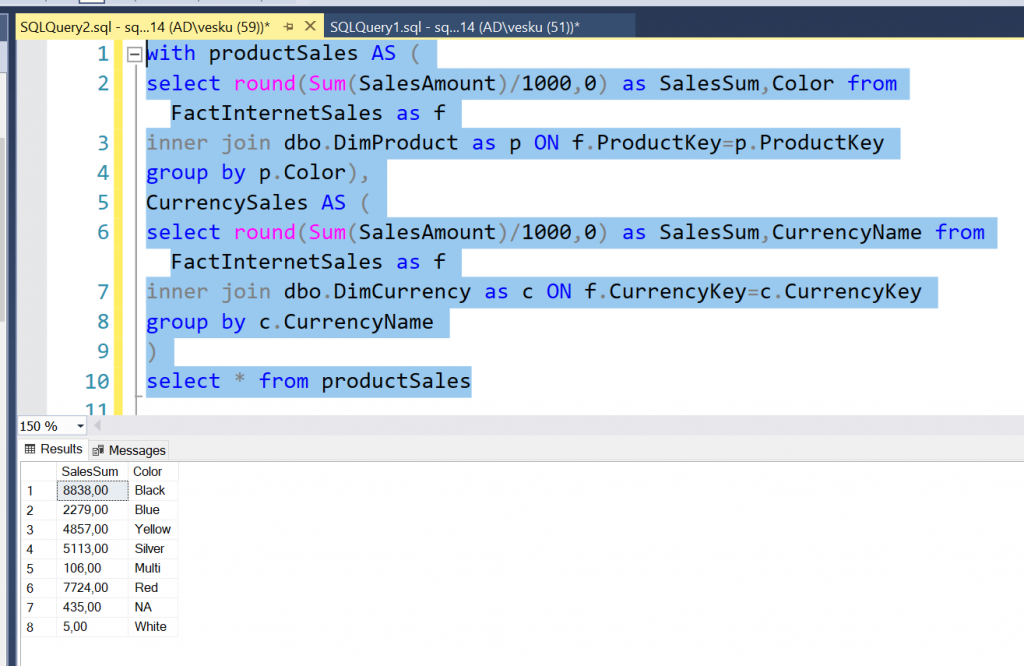
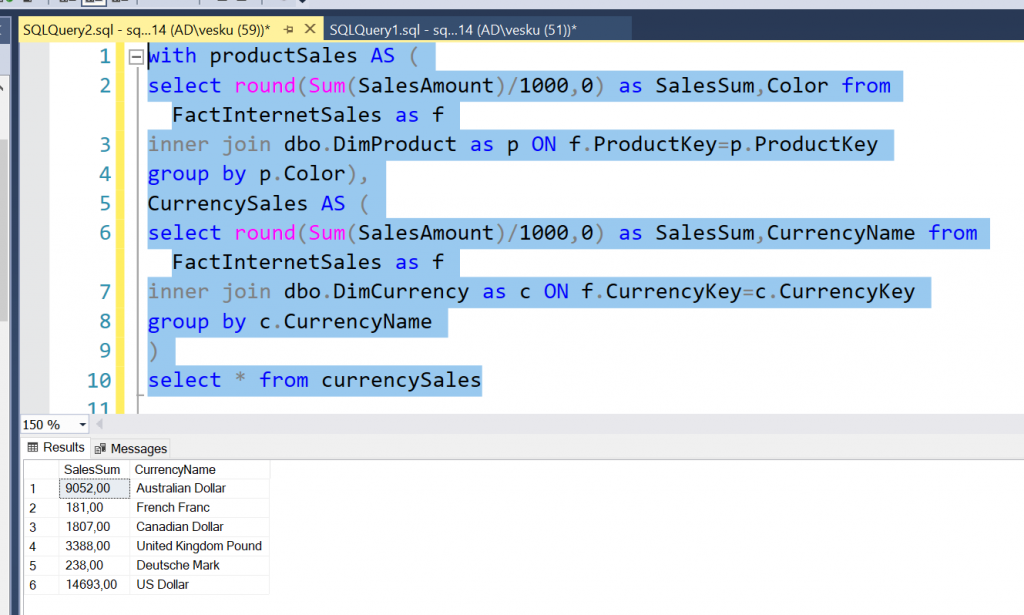
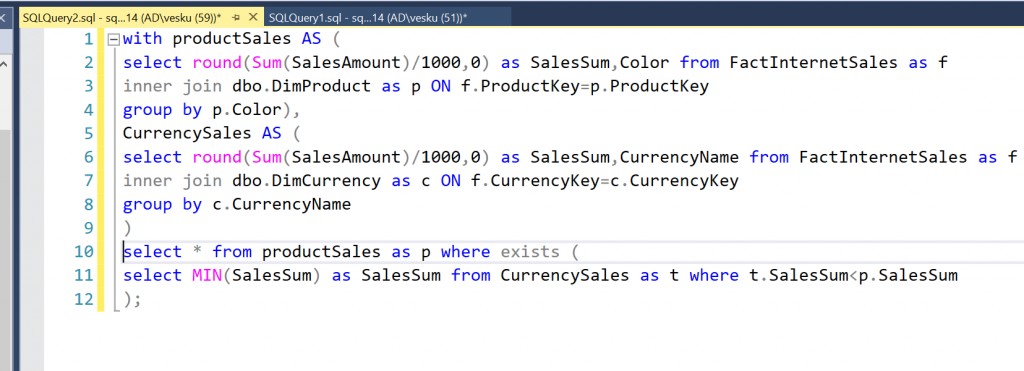
Vastauksia tuli 4 kpl. Yhdessä vastauksessa kritisoitiin termistöä, joka oli itseasiassa ihan oikein! Juoksin tehtävän liian nopeasti, enkä käyttänyt oikeaa termiä “Tasaerä”.. Eli jokainen payment olisi saman kokoinen, sen takia vastauksia tuli pari erilaista, enkä voi sanoa kummankaan olevan väärin. Tavoitteenani oli käyttää termiä “tasaerä”, jolloin jokainen kk-maksu on aina yhtä iso. Ja oikeastaan tarkoituksena oli avata sitä että DAX:ssa on tosi paljon funktioita valmiina. Sellainen funktiolistan läpikäynti: DAX function reference – DAX | Microsoft Docs aina välillä olisi oikeasti ihan hyödyllistä ajankäyttöä!
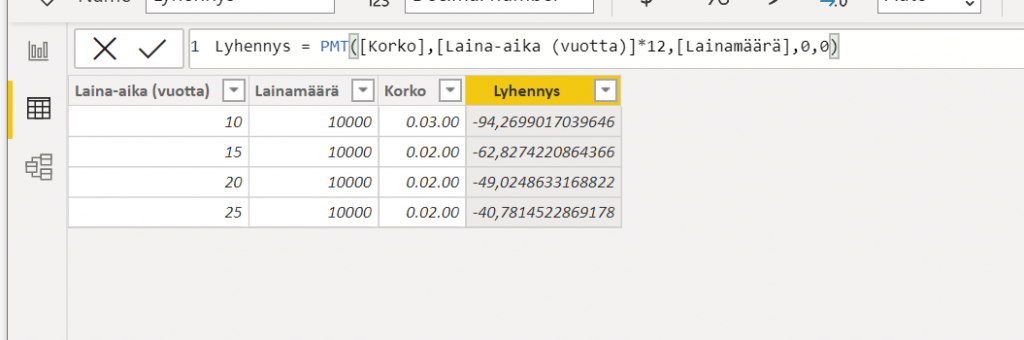
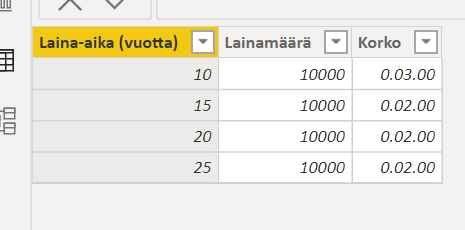
Koodi, jolla tuohon datasettiin saa lyhennyksen näkyviin on: Lyhennys= PMT([Korko],[Laina-aika (vuotta)]*12,[Lainamäärä],0,0)
Päivän pähkinän ei pitäisi olla kovinkaan vaikea! Eli vähän laina-matematiikkaa. Tarkoitus olisi oheiseen tauluun lisätä sarake, joka laskee kk-maksun. Eli paljonko lainaa tulee maksaa kuukaudessa takaisin. Lainaa lyhennetään tasalyhennyksellä jokaisen kuukauden lopussa. Laina on nostettu kuukauden alussa.
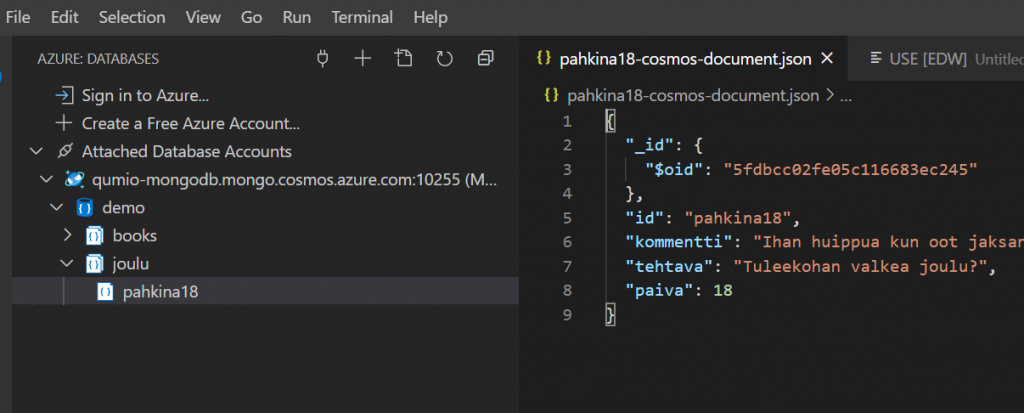
Ensi viikolla on Joulu! Pähkinässä 18 otetaan yhteys MongoDB tietokantaan CosmosDB:n sisällä. Tehtävä on siis ottaa oheisella connection stringillä yhteys Cosmos DB:hen ja lukea sieltä collection: “joulu”. Siellä on yksi dokumentti, jossa on attribuutti “tehtava”. Palauta kyseinen kysymys ja vastaa siihen omin sanoin.
Joulupähkinään 17 tuli ratkaisuja 8 kpl. Kaikki olivat oikein! Kiitos kun vielä moni jaksaa vastailla. Nyt alkaa kyllä ihan samat nimet toistua melkein jokoa päivä 🙂
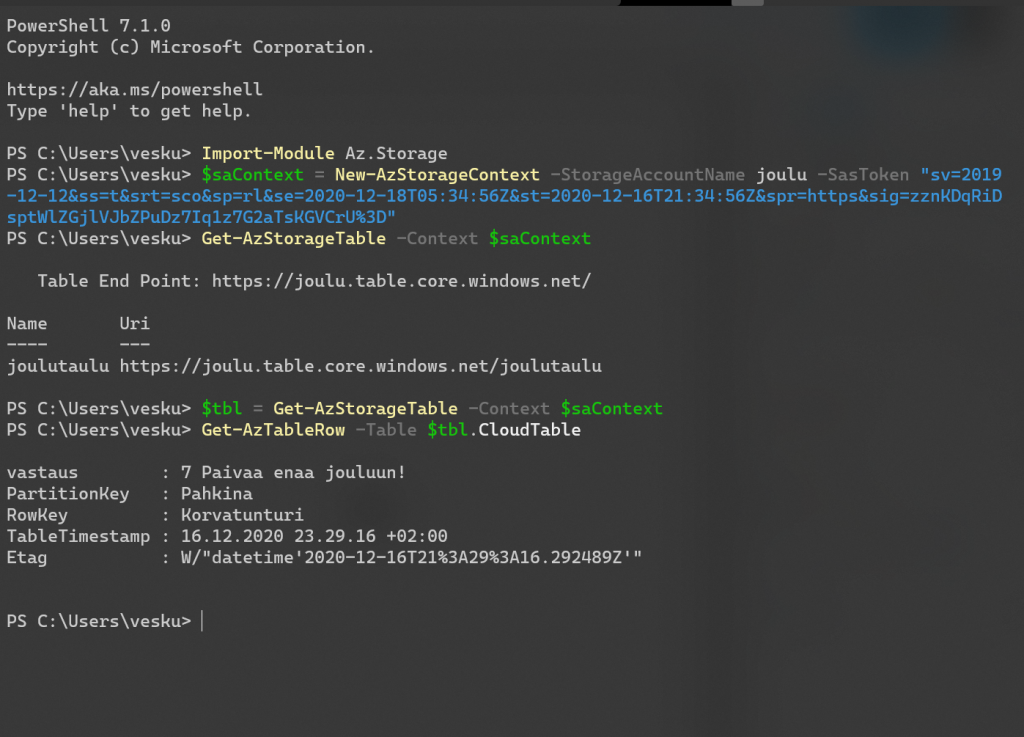
Käytin yhteyden muodostamiseen PowerShelliä. Ratkaisu meni seuraavasti:
Joulupähkinä #17 vie meidät nosql maailmaan ja tarkemmin Azure Storagen Table-apiin. Tehtävänäsi on hakea taulun sisältö ja palauttaa siellä oleva viesti vastauksessasi. Tauluja on accountissa 1 ja siinä taulussa on 1 objekti, joten mitään kauhean vaikeaa etsimistä ei tarvitse tehdä.
Azure Storagen Table api on hyödyllinen myös dataihmisille, jos on tarve säilöä dokumenttipohjaista dataa. Tietenkin Cosmos DB on ykkösvaihtoehto, mutta ei se Storage Table tarpeeton ole. Tämä ominaisuus on kuitenkin monelle jäänyt vähän ohuelle, joten tutustutaan siihen!
Tarvitsemasi SAS-avain on: https://joulu.table.core.windows.net/?sv=2019-12-12&ss=t&srt=sco&sp=rl&se=2020-12-18T05:34:56Z&st=2020-12-16T21:34:56Z&spr=https&sig=zznKDqRiDsptWlZGjlVJbZPuDz7Iq1z7G2aTsKGVCrU%3D
Kuten sanottu, palauta vastauksessasi viesti jonka löydät tablesta.
Common Table Expression… Yhtä vastausta mukaillen: “Rekursio sattuu aina päähän.” … Välttämätön paha kaikenlaisessa rakenteellisissa kyselyissä ja joka kerta joutuu kattoon sitä samaa Microsoftin esimerkkiä 🙂
Mutta hienoa, 6 vastausta, kaikki oikein! Tässä yhden palautuksen koodi esimerkkivastauksena:
WITH CTE AS ( SELECT EmployeeKey, ParentEmployeeKey, convert(varchar(max), FirstName + ‘ ‘ +LastName) as fullname FROM DBO.DimEmployee WHERE ParentEmployeeKey IS NULL UNION ALL SELECT t.EmployeeKey, t.ParentEmployeeKey, c.fullname + ‘/’ + convert(varchar(max), t.FirstName + ‘ ‘ + t.LastName) FROM DBO.DimEmployee t INNER JOIN CTE c on c.EmployeeKey = t.ParentEmployeeKey ) select e.*, c.fullname as organisaatio from DimEmployee e left join CTE c on e.EmployeeKey = c.EmployeeKey
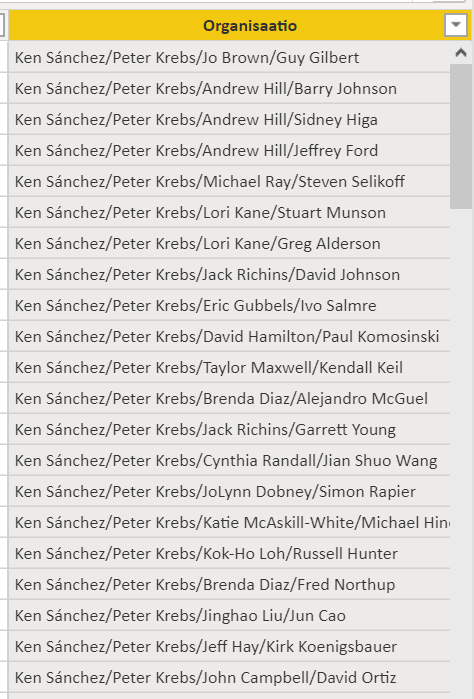
Joulupähkinä #16 ponnistaa siitä mihin eilinen jäi! Eli kun katsoimme rekursiota DAX:lla, niin nyt sitten rekursiota SQL:llä. Kysymys on sama, eli Tee dbo.dimEmployee taulua vasten kysely, jossa muodostat alkuperäisen taulun+yhden uuden sarakkeen jossa on polku toimitusjohtajasta työntekijään.
Käytännössä siis SQL-selectin joukon tuloksen tulisi näyttää jotakuinkin tällaiselta sen uuden kolumnin osalta:
Ken on siis firman johtaja, jolla on Peter alaisena, jonka alaisena toimii Jo ja hänen alaisensa on Guy. Tämä sama päätelmä tulee laskea jokaiselle riville. Et saa lisätä selectiin kuin yhden kolumnin. Kaikki koodi on siis kirjoitettava yhteen lauseeseen, eikä tietokantaan saa luoda pysyväisobjekteja (#-tauluja tai normitauluja). Erotinmerkki on /-merkki.
Tämä oli nyt selkeästi liian työläs… 6 vastausta, 2 tietyllä tavalla oikeaa, mutta ihan kauhean työlästä vastausta, jossa puurakenne oli purettu auki ja käsin haettiin jokainen taso eri muuttujaan jotka yhdistettiin. 4 hyvää yritystä.
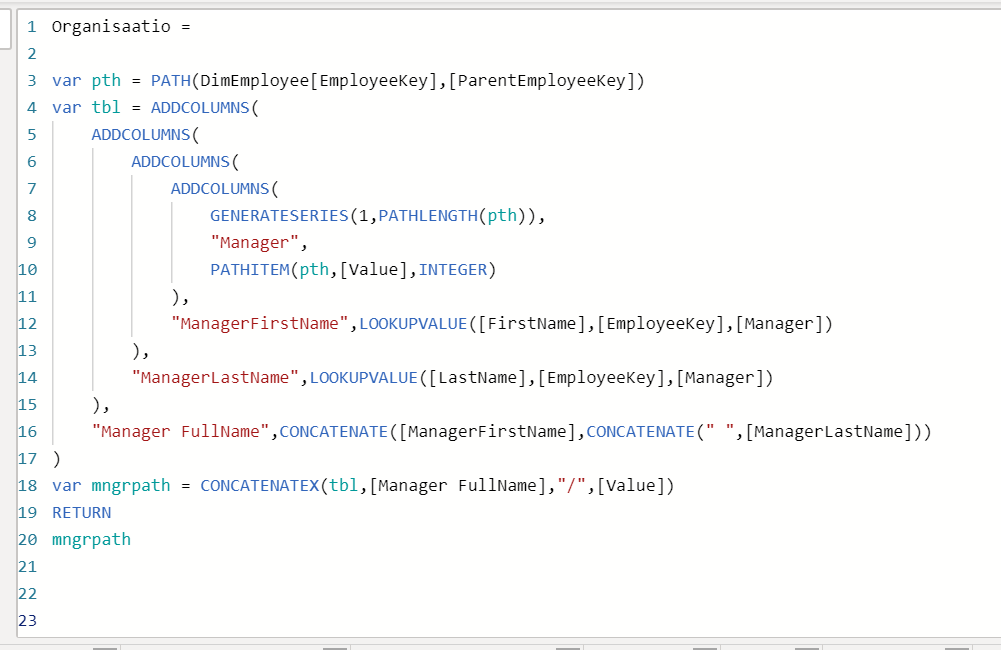
Eli ensiksi rivillä 3 rakennetaan path-olio. Sitten luodaan aputaulu generateseries-funktion avulla (se tekee taulun, jossa on yksi kolumni, joka on Value ja sitten riveillä numerot 1,2,3…n, jossa n=pathlength.
Sitten siihen tauluun voidaan liittää managerin id tuolla pathitem funktiolla. Sen jälkeen parilla lookup-kierroksella voidaan hakea noi etunimi ja sukunimi arvot (yhdistän ne sen jälkeen fullnameksi). Ja sit lopulta contatenatex-funktiolla näppärästi yhdistetään kaikki rivit takaisin yhdeksi arvoksi, jolloin se voidaan palauttaa.
Rekursioita tarvitsee DAX:ssa aina välillä. Nyt olisi tavoitteena laajentaa DimEmployee -taulua yhdellä kolumnilla. Tässä kolumnissa olisi arvoina kaikki henkilöt yrityksen toimitusjohtajasta aina kyseisen rivin henkilöön saakka erotinmerkillä eroteltuina. Käytännössä siis kentän tulosjoukko näyttää seuraavalta:
Ken on siis firman johtaja, jolla on Peter alaisena, jonka alaisena toimii Jo ja hänen alaisensa on Guy. Tämä sama päätelmä tulee laskea jokaiselle riville. Et saa lisätä malliin kuin yhden kolumnin. Kaikki koodi on siis kirjoitettava tämän kolumnin esittelyyn. Erotinmerkki on /-merkki.
Palauta kolumnin lisäyskoodisi vastauksessasi.
Tehtävässä tarvitsemasi Power BI desktop tiedoston voit ladata oheisesta linkistä.
Pähkinään #15 tuli 7 vastausta, joista kolme oli juuri se ominaisuus, jota minä hain. Calculation Groupit ovat ihan uusi ominaisuus, jolla voi tehdä contextinvaihtosuureita. Eli juuri suureita joka laskevat saman asian kuin aikaisemmin, mutta toisessa kontekstissa, kuten esimerkiksi erilaisella Wherellä.
Nyt asiakkaalle oli vanhempi Analysis Services ja minun oli pakko päätyä ratkaisuun, jossa oli välitaulu. Käytännössä siis 2 uutta taulua niin että keskimmäisessä taulussa oli kaksi kolumnia “koko” ja “linkkiId”. Tässä oli *-liitos ja toisessa päässä aina 1-liitos. Sitten toinen uusi taulu, jossa oli “linkkiId” ja “muuttujajoukko”, jossa muuttujajoukko sai arvot “all” ja “without44”. Sitten suodatus 2-suuntaisilla nuolilla. Käytännössä tällöin pystyi filteroimaan tällä uudella taululla ja datajoukko osittui oikein. Mutta paljon elegantimpi ratkaisu on tuo calculation groups.
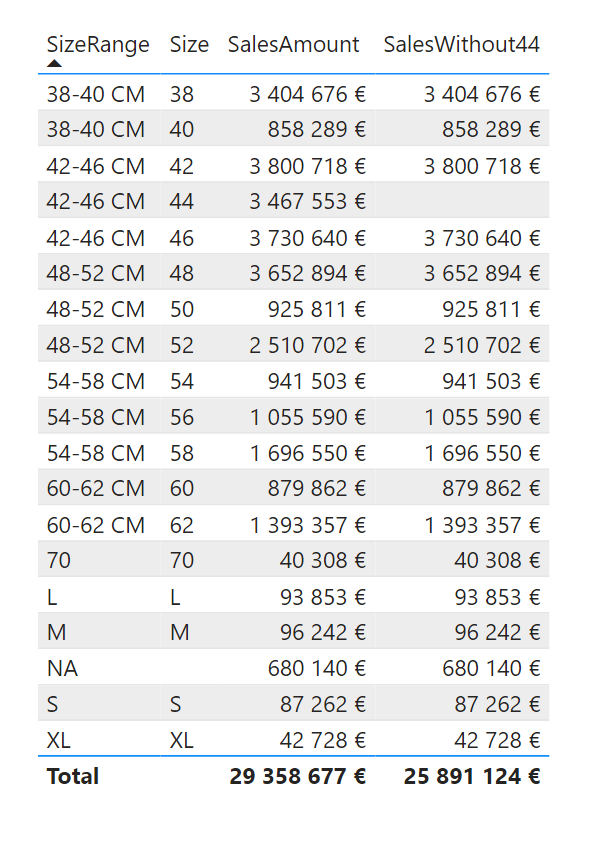
Joulupähkinä #14 on yksi oikea asiakascase, tosin tietty data on eri kun tässä mennään AdventureWorksilla. Kyseessä on malli, jossa on n. 50 erilaista mittaria (suuretta). Jokaisesta mittarista tulisi saada versio, jossa yksi koko-komponentti otetaan pois. Tämä sen takia, että tietyissä laskennoissa sillä on väliä, toisissa ei niin paljoa.
Oheinen kuva kuvastaa tilanteen. Mittari on Sum([SalesAmount]) ja siitä on toinen versio, jonka koodi on:
SalesWithout44 = var size = VALUES(‘DimProduct'[Size]) RETURN CALCULATE(SUM(‘FactInternetSales'[SalesAmount]),’DimProduct'[Size]<>”44″, ‘DimProduct'[Size] in size)
Nyt tuo sama Without44 – tyyppinen laskenta pitäisi saada kaikille 50 muulle mittarille. Tietty voisi tehdä toiset mittarit ja mallissa olisi sen jälkeen 100 mittaria, mutta ei olisi käytännöllistä, eikä asiakas ole valmis maksamaan tuollaisesta apinan hommasta ja siitä seuraavasta ylläpitovaivasta sen jälkeen. Miten siis saisimme jotenkin järkevästi molemmat mittarit käyttöön ilman että kaikkea tulee kopioida.
Erilaiset mittarit ovat siis:
Ihan normaali, kuten nytkin.
Muuten sama, mutta tulee ottaa pois DimProduct[Size]=44, eli tuota ei tule huomioida missään mittarissa.
Minun tapauksessani asiakkaalla oli Analysis Services 2017, joten lopputulos ei oo niin elegantti, kuin se voisi olla mutta sinä saat tehdä sen käyttäen kaikkia viimeisimpiä komponentteja.
Vastaa kuvauksella mitä tekisit, ei tartte pilkuntarkasti kuvata jokaisen mahdollisen koodin syntaksia, vaan ratkaisumalli.
Ensiksi: Sain palautetta että pähkinä on myöhässä! Ihan huippua, sunnuntaina oltiin valmiina pähkinään ja minä nukuin myöhään… Pyydän anteeksi. Mutta samalla olen tosi otettu siitä että ratkaisette näitä pähkinöitä! Vastauksia tuli 6kpl vaikka en edes mainostanut tämän päivän pähkinää kun olin koko päivän lasten harrastuksissa.
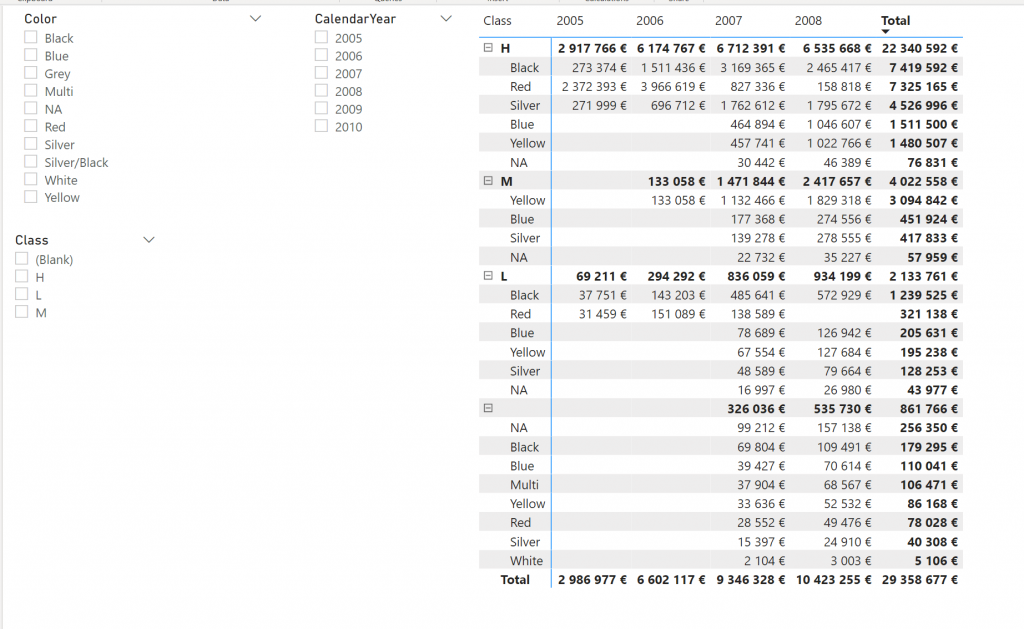
Vastaus: 22 067 218 Oikean vastauksen sai 3 henkilöä, pitää lukea vähän tarkemmin mikä noissa muissa meni metsään, eli miten vastaaja on ymmärtänyt tuon väärin. Tärkeät jutut ovat kuitenkin:
VAR sumvalue – tämä evaluoidaan esittelyn yhteydessä. Tähän ei siis vaikuta myöhemmät filterit vaan sumvalue muuttujassa on ihan numero sisällä (ei siis koodia joka suoritettaisiin myöhemmin). Se saa siis arvon: 273 374.
VAR classvalues – tämä on taulukko, jossa on yksi kolumni (joku voisi sanoa lista arvoista), mutta tätä ei käytetä varsinaisessa suureessa, joten tästä ei tartte välittää.
CALCULATEN – Sum on siis ‘DimProduct’-taulusta kaikki muut, paitsi Class-filter. Se vie siis tavallaan lihavoidulle riville “H”, koska H oli class. Sitten ALL(DimDate) poistaa aika-filterin, jolloin mennään H-rivin loppuun Total-sarakkeelle. Saadaan arvo 22 340 592. Tämä tulee Sum-funktiosta, siitä sitten vähennetään tuo sumvalue-muuttujan arvo. Eli: 22340592-273374 = 22067218
Se, mitä halusin tässä tuoda esiin on tuo VAR-evaluoidaan aina silloin kun se esitellään. Sillä voi oikeasti tehdä aika jänniä juttuja kun antaa mahdollisuuden käsitellä lukuja ihan eri laskentacontexteista.
Pähkinä #13 menee VAR,Return, Calculate laskentakontekstien juurelle. Kysymys kuuluu, Mikä luku palautuu kohtaan:
Class=H Color=Black Year=2005
Näet näytöllä luvut, kuten ne ovat silloin kun käytetään suuretta SUM(‘FactInternetSales'[SalesAmount]),
Jos suure vaihdetaan seuraavaksi:
Sales2 = VAR classvalues = values(‘DimProduct'[Class]) var sumvalue=CALCULATE(SUM(‘FactInternetSales'[SalesAmount])) RETURN CALCULATE(SUM(‘FactInternetSales'[SalesAmount])-sumvalue,ALLEXCEPT(‘DimProduct’,DimProduct[Class]),ALL(‘DimDate’))
Mitä tulee ko. kohtaan? Class=H Color=Black Year=2005
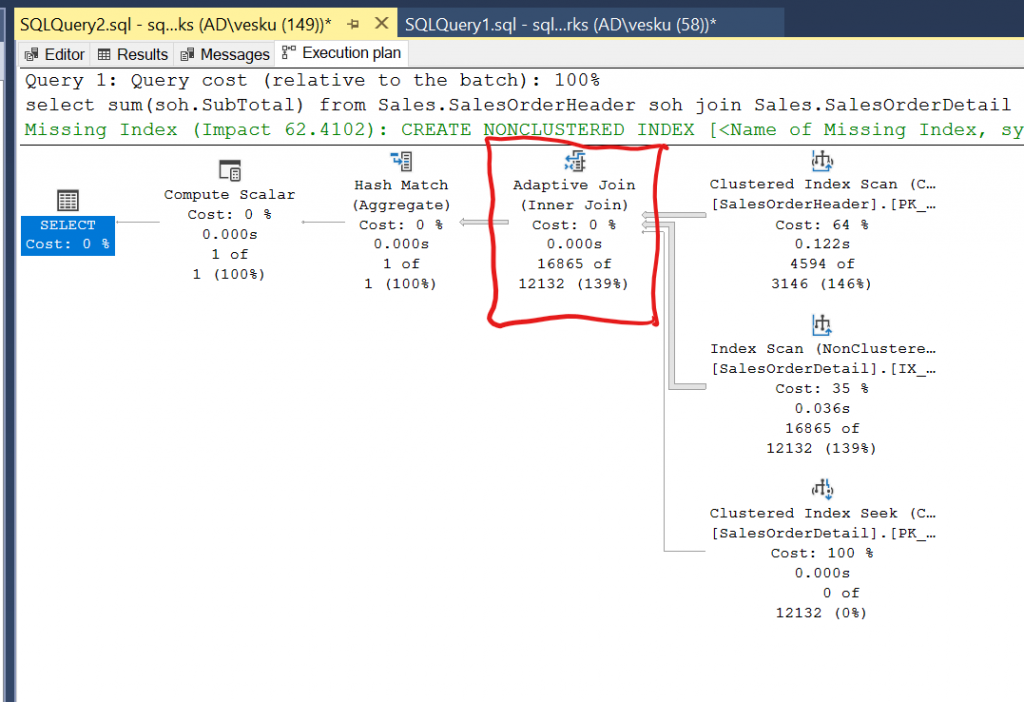
Pähkinässä #12 ihmeteltiin uutta adaptiivista join-operaattoria SQL Serverissä. Ko. operaattori avasi portit dynaamiselle suoritussuunnitelmalle! Aikaisemmin SQL Server päätti tehdä jotain etukäteen ja sitten itsepäisesti suoritti ko. operaattoria vaikka arvaus olisi mennyt metsään.
Nyt tämä uusi operaattori mahdollistaa kyselylle suoritussuunnitelman tallentamisen ja sitten annettujen parametrien perusteella se voi tilastoista päätellä kumpaa haaraa se alkaisi suorittamaan. Ja sitten jos suorituksen aikana arvaus menee pieleen, se voi vielä vaihtaa operaattoria lennosta. Tämä operaattorin vaihtaminen on harvinainen, mutta tilanteessa missä adaptiivinen join on tehnyt HASH-match vs. NestedLoop parin ja lähtee liikkeelle nestedloopilla, voi operaattori vaihtaa scaniin jos looppi palauttaakin ihan liikaa rivejä arvaukseen nähden. Tämä sen takia, että loopissa joka iteroinnilla saadaan vain yksi arvo ja jos työmäärä arvon saamiseksi on yhtään isompi, voi scan olla itseasiassa paljon nopeampi tapa.
Vastauksia tuli 3, kaikki olivat vähän eri sanamuotoja mutta just oikein! Huhupuheita on ollut että adaptiivisuus tulee myös muutamaan muuhun operaattoriin, kuten sort-group tai hash-group tyyppisiin rakenteisiin, toivottavasti nähdään!
SQL-ongelma: Luo parhaat mahdolliset indeksit kyselylle. Kyselyä et saa muuttaa muilta osin, kuin lähdetaulujen nimien suhteen, koska joudut luomaan kopion olemassa olevista tauluista. Yritä saada mahdollisimman tehokas indeksi niin, että levyoperaatiot jäävät mahdollisimman pieniksi.
Kysely, josta saat siis muuttaa vain taulujen nimiä niiltä osin, kuin olet ottanut kopion alkuperäisistä tauluista:
select sum(SalesAmount), c.CurrencyName,d.DayNumberOfWeek from dbo.FactInternetSales –tätä riviä saa muuttaa as f inner join dbo.DimCurrency –tätä riviä saa muuttaa as c ON f.CurrencyKey=c.CurrencyKey inner join dbo.DimDate –tätä riviä saa muuttaa as d ON f.OrderDateKey=d.DateKey where d.EnglishMonthName=’April’ group by c.CurrencyName,d.DayNumberOfWeek;
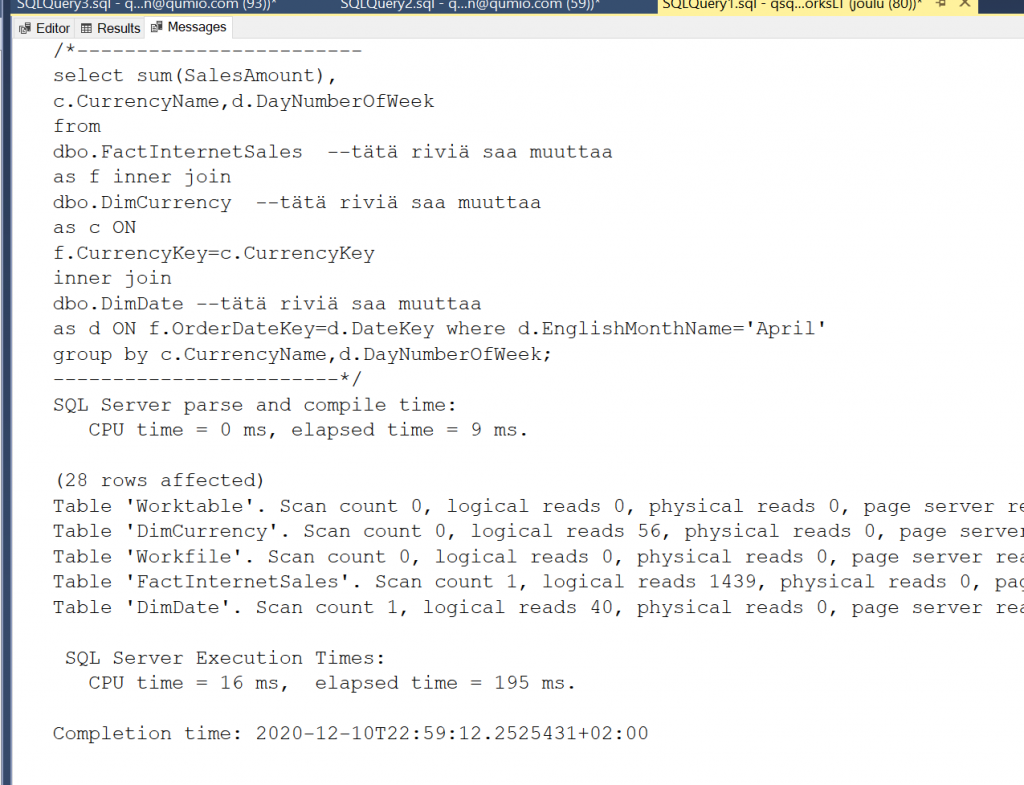
Kun ajat komentoa, laita tilastot näkyviin komennoilla:
set statistics io on; set statistics time on;
Silloin saat messages-välilehdelle näkyviin montako loogista levy-io:ta kysely teki. Ilman mitään muutoksia tulos näyttää tältä:
Eli kysely teki yhteensä: 0+56+0+1439+40 = 1535 levy-io:ta. Tuon alle pitäisi päästä mahdollisimman paljon.
Saat luoda tauluista kopion ottamalla select * into jouludelete.omataulu… Eli Esimerkiksi: select * into jouludelete.FactInternetSales_vesa from dbo.FactInternetSales
Sen jälkeen sinulla on oikeus luoda indeksejä tuohon luomaasi tauluun ja tietenkin sitten muutat selectiä niin että se kyselee siitä sun versiosta, eikä alkuperäisestä. Palauta tuo levy-io listaus ihan sellaisenaan ja mielellään valmiiksi laskettuna summa noista loogisista levy-io:sta.
Vastauksia tuli 6 kpl, joten nyt oli taas tylsä tai jotain… Mutta harmittavasti ei ainoatakaan oikeaa vastausta. Pähkinän vaikea knoppi oli se, että Azure Data Factory laskuttaa jokaisesta laatikosta jonka se suorittaa käytetyn ajan, tai vähintään 1 minuutin. Tämä 1 minuuttia voi näytellä tällaisissa loopeissa tosi isoa merkitystä.
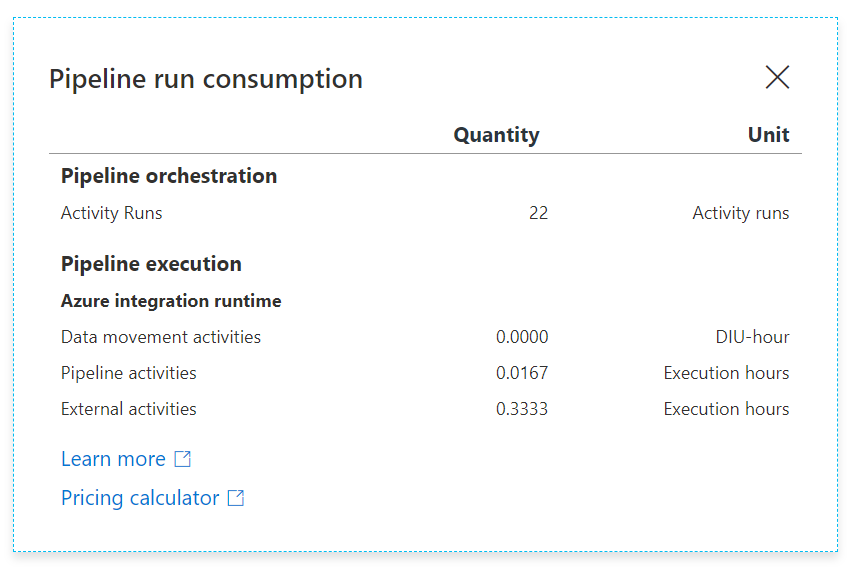
Tein esimerkkiajon niin että tuo lookupin palauttava objekti oli 10 riviä, jolloin suoritusaika oli seuraava:
External activities on noita stored proceja. Niitä on siis 20, koska 10 kertaa 2 procia. Se on 0,333h, eli 0,333*60 = 20 minuuttia. Lisäksi tulee pipeline aktiviteetteja 0,016h, eli 0,16*60 = 1. Tämä tarkoittaa siis sitä ekaa lookupia.
Jos tuon olisi pyöräyttänyt 500 objektille, olisi kustannus ollut
1 min pipeline
1000 min external activities
yhteensä 1001 minuuttia, eli 16,7 tuntia, vaikka suoritus olisi ollut ohi 2 minuutissa. Kustannuksia tämä testi olisi aiheuttanut (1000/60)*0,085eur + (1/60)*0,211 eur = 1,4 euroa.
Tämä on yksi Data Factoryn väärin ymmärretyin ominaisuus. Se on tosi hyvä vekotin siirtämään dataa paikasta toiseen, mutta jos sitä käytetään kuten SSIS:ää on aina käytetty, mennään metsään ja pahasti.