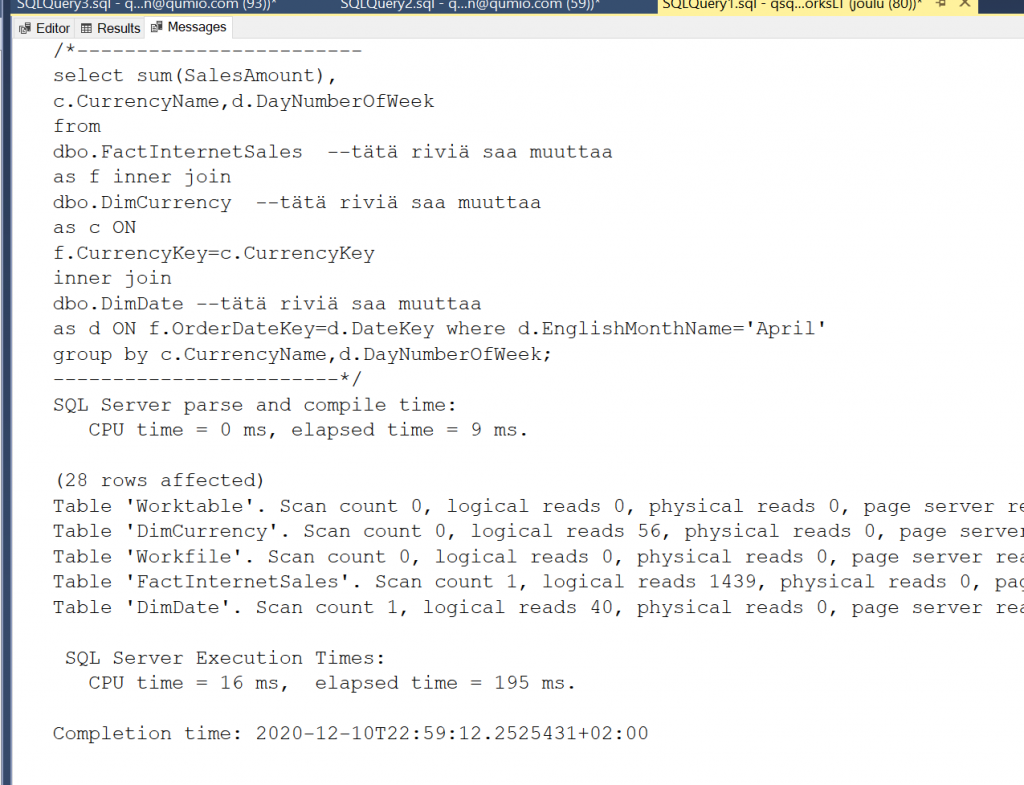
Rekursioita tarvitsee DAX:ssa aina välillä. Nyt olisi tavoitteena laajentaa DimEmployee -taulua yhdellä kolumnilla. Tässä kolumnissa olisi arvoina kaikki henkilöt yrityksen toimitusjohtajasta aina kyseisen rivin henkilöön saakka erotinmerkillä eroteltuina. Käytännössä siis kentän tulosjoukko näyttää seuraavalta:
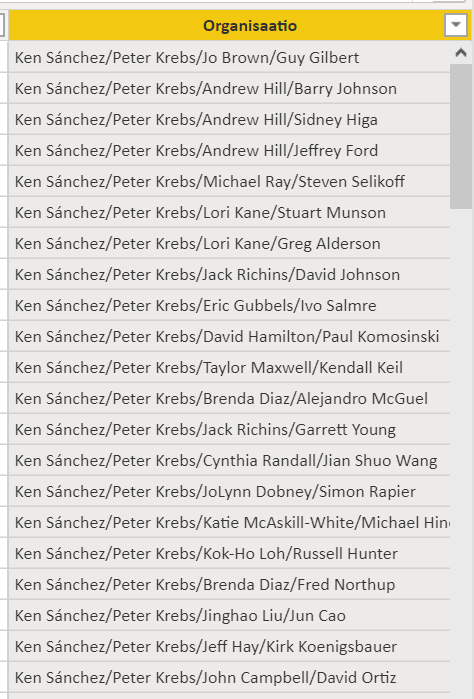
Ken on siis firman johtaja, jolla on Peter alaisena, jonka alaisena toimii Jo ja hänen alaisensa on Guy. Tämä sama päätelmä tulee laskea jokaiselle riville. Et saa lisätä malliin kuin yhden kolumnin. Kaikki koodi on siis kirjoitettava tämän kolumnin esittelyyn. Erotinmerkki on /-merkki.
Palauta kolumnin lisäyskoodisi vastauksessasi.
Tehtävässä tarvitsemasi Power BI desktop tiedoston voit ladata oheisesta linkistä.
Jos haluat palauttaa pähkinän, onnistuu se tuttuun tyyliin Microsoft Forms-lomakkeella.
Pähkinän #15 vastaus – Calculation group
Pähkinään #15 tuli 7 vastausta, joista kolme oli juuri se ominaisuus, jota minä hain. Calculation Groupit ovat ihan uusi ominaisuus, jolla voi tehdä contextinvaihtosuureita. Eli juuri suureita joka laskevat saman asian kuin aikaisemmin, mutta toisessa kontekstissa, kuten esimerkiksi erilaisella Wherellä.
Niihin on hyvä ohje osoitteessa: Calculation groups in Analysis Services tabular models | Microsoft Docs
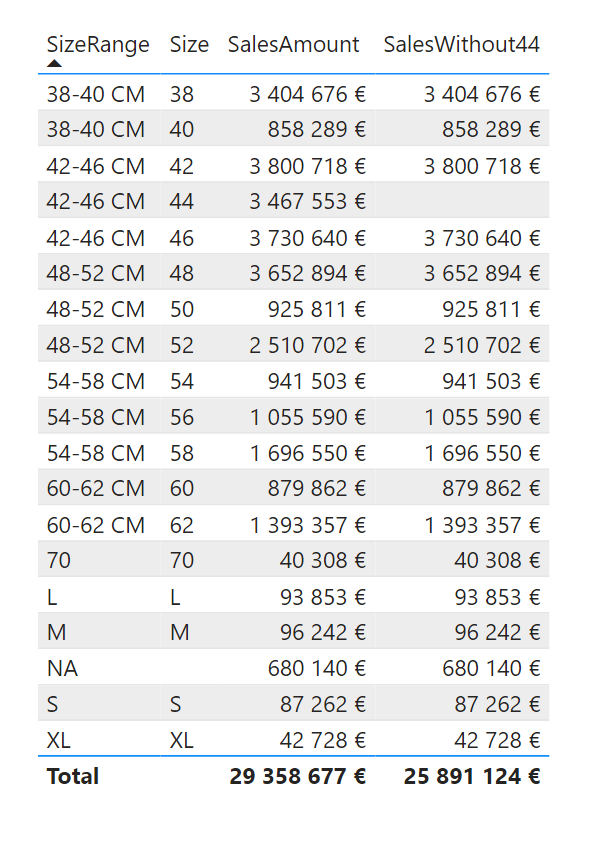
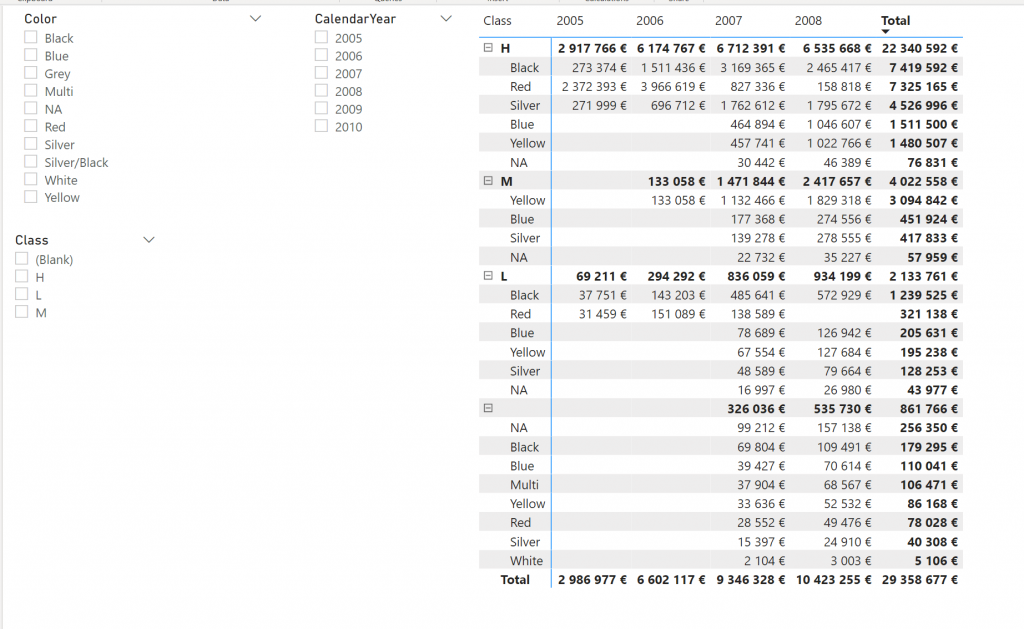
Nyt asiakkaalle oli vanhempi Analysis Services ja minun oli pakko päätyä ratkaisuun, jossa oli välitaulu. Käytännössä siis 2 uutta taulua niin että keskimmäisessä taulussa oli kaksi kolumnia “koko” ja “linkkiId”. Tässä oli *-liitos ja toisessa päässä aina 1-liitos. Sitten toinen uusi taulu, jossa oli “linkkiId” ja “muuttujajoukko”, jossa muuttujajoukko sai arvot “all” ja “without44”. Sitten suodatus 2-suuntaisilla nuolilla. Käytännössä tällöin pystyi filteroimaan tällä uudella taululla ja datajoukko osittui oikein. Mutta paljon elegantimpi ratkaisu on tuo calculation groups.